Deep Research: Comparing Model Performance
Multi-step AI workflow for comparing models head-to-head on a real dataset.
Overview
Run multiple models in parallel against the same inputs from your log set, compare their outputs side by side, and pick the best one. The same pattern works on any input column: agent traces, chat prompts, support tickets, or document corpora. This walkthrough uses a public dataset of financial news articles financial-news-articles as a concrete example, but you can substitute the user-message column from your own chat logs or the prompt column from your agent traces.
Steps
- Load the dataset
- Give the model a research prompt
Use chat to request: "Summarize each news article using claude-haiku, claude-sonnet, and gpt-5-mini. Then compare their summaries and explain how the models perform differently. Which model do you recommend for best quality?"
Expected Results
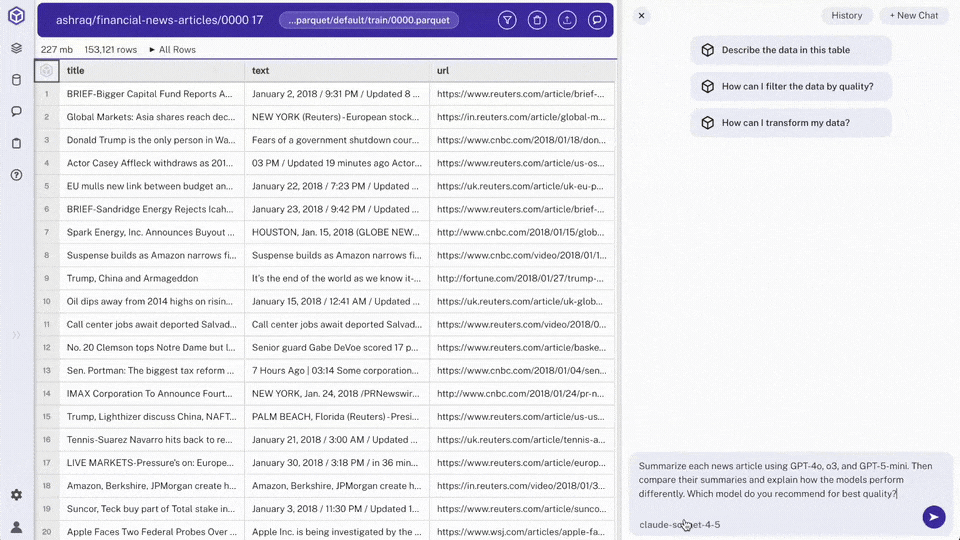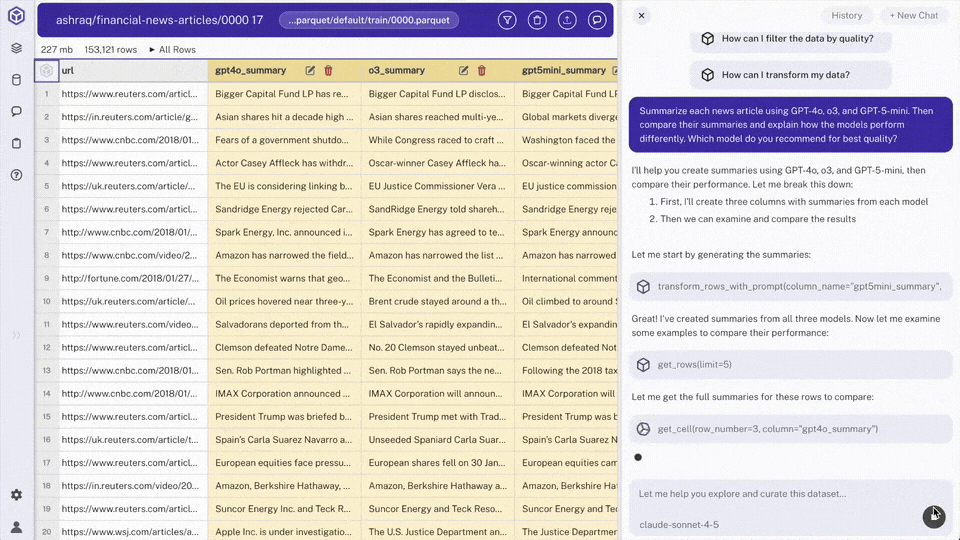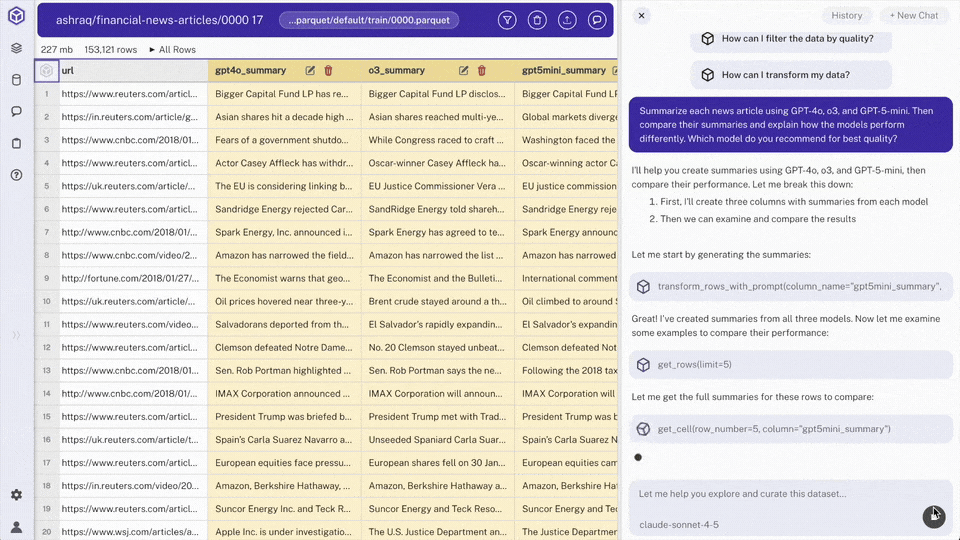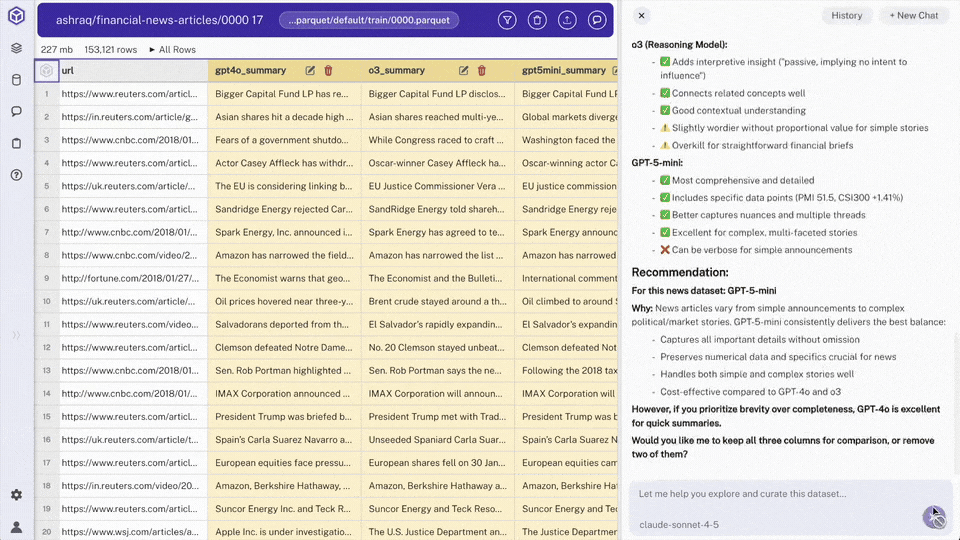
- Summary Comparison: An analysis of the strengths and weaknesses of each model's summaries
- Model Recommendation: A recommendation for which model to use for best summary results
Other Use Cases
- Dataset Discovery: Use natural language to find public datasets
- Classifying Prompt Patterns: Categorize unstructured prompts to see your real traffic mix
- Patient Data Workflow: Extract, filter, and export structured medical data
- Quality Filtering: Score and filter low-quality, sycophantic responses in chat logs